pacman::p_load(afex,
dplyr,
effectsize,
emmeans,
flextable,
ggbeeswarm,
ggplot2,
ggpubr,
ggsci,
knitr,
readxl,
rstatix,
tidyr)16 Anova de Medidas Repetidas
16.1 Pacotes usados neste capítulo
16.2 Anova de Medidas Repetidas com um Fator
16.2.1 Introdução
A ANOVA de medidas repetidas (Repeated Measures ANOVA) é uma técnica estatística usada quando o mesmo grupo de participantes é medido várias vezes, seja ao longo do tempo ou sob diferentes condições. Ela é ideal para dados longitudinais ou experimentos intra-sujeitos, onde cada sujeito serve como seu próprio controle. São exemplos típicos:
• Medir a qualidade de vida de crianças asmáticas em vários momentos para avaliar o impacto de um programa de atenção ao asmático;
• Testar tempos de reação em um teste em três tempos em um mesmo grupo;
• Testar a autoestima de um mesmo grupo após a introdução de um tipo especial de dieta.
A Tabela 16.1 mostra algumas diferenças importantes entre a ANOVA e a ANOVA de Medidas Repetidas:
Característica | ANOVA (entre sujeitos) | ANOVA de Medidas Repetidas (intra-sujeitos) |
|---|---|---|
Tipo de Amostra | Grupos independentes | Mesmos sujeitos em diferentes condições |
Controle da variabilidade individual | Não controla | Controla (cada sujeito é seu próprio controle) |
Sensibilidade estatística | Menor | Maior (reduz o erro residual) |
Suposição de esfericidade | Não se aplica | Necessária (testada com o teste de Mauchly) |
A ANOVA de medidas repetidas é mais poderosa estatisticamente porque reduz a variabilidade entre sujeitos, focando nas mudanças dentro de cada indivíduo. A ANOVA de medidas repetidas pode ser entendida como uma expansão da ANOVA (1).
A ANOVA de medidas repetidas de um fator é uma técnica estatística que compara as médias de três ou mais grupos relacionados, onde os mesmos participantes são medidos repetidamente em diferentes momentos ou condições para avaliar a mudança em uma variável dependente. É uma extensão do teste t pareado para mais de dois grupos e, por avaliar o mesmo grupo ao longo do tempo, controla diferenças individuais.
16.2.2 Dados usados no exemplo
Cenário do exemplo
Um estudo, realizado em um ambulatório de Doenças Respiratórias Pediátricas, avaliou a função pulmonar de um grupo de crianças por um período de 3 meses (0, 45 dias, 90 dias) usando um novo corticoide inalatório. Todas as crianças tinham idade entre 7 e 15 anos e a medida avaliadora foi PFE (Pico de Fluxo Expiratório) que corresponde a taxa máxima de ar expelida pelos pulmões durante uma expiração forçada, indicador importante da função pulmonar, especialmente no monitoramento de asma.
Os dados podem ser obtidos aqui. Baixe no seu diretório de trabalho e carregue com a função read_excel() do pacote readxl. Na ANOVA de medidas repetidas de um fator, será usado apenas o grupo, denominado de caso, que usou o medicamento testado.
dados_uni <- readxl::read_excel("dados/dadosAsma.xlsx") |>
dplyr::filter(grupo == "caso") |>
dplyr::select(id, t0, t1, t2)
str(dados_uni)tibble [41 × 4] (S3: tbl_df/tbl/data.frame)
$ id: num [1:41] 1 2 3 4 5 6 7 8 9 10 ...
$ t0: num [1:41] 170 100 160 180 250 180 170 180 240 200 ...
$ t1: num [1:41] 180 140 180 180 300 200 180 200 320 200 ...
$ t2: num [1:41] 220 100 220 250 240 280 220 250 350 250 ...16.2.2.1 Exploração e transformação dos dados
Observando a saída da função str(), verifica-se os dados se encontram no formato amplo (a variável tempo está colocada em três colunas, t0, t1, t2) e a ANOVA de medidas repetidas necessita de que os dados estejam no formato longo. Isso significa que, ao invés de ter cada medida repetida em uma coluna separada, haverá uma coluna para o identificador (id) do indivíduo, uma coluna para o tempo/condição (fator de medidas repetidas), e uma coluna para o valor da variável dependente (VD = escores).
Para fazer esta transformação será realizada pela função pivot_longer()1do pacote tidyr (2). Nesta função, no argumento data, coloca-se o nome do conjunto de dados; em cols, há necessidade informar as colunas do formato amplo que serão reunidas. No argumento names_to, nomear a coluna que conterá as colunas unificadas e em values_to, especificar o nome da variável no formato longo que conterá os valores. A variável id e a nova variável tempo devem ser convertida para fatores e o novo conjunto de dados será atribuído a um objeto nomeado dadosL_uni:
1 Veja a Seção 14.3.1.1 para mais detalhes da função
dadosL_uni <- dados_uni |>
tidyr::pivot_longer(cols = c(t0, t1, t2),
names_to = "tempo",
values_to = "escores") |>
convert_as_factor(id, tempo)
str(dadosL_uni)tibble [123 × 3] (S3: tbl_df/tbl/data.frame)
$ id : Factor w/ 41 levels "1","2","3","4",..: 1 1 1 2 2 2 3 3 3 4 ...
$ tempo : Factor w/ 3 levels "t0","t1","t2": 1 2 3 1 2 3 1 2 3 1 ...
$ escores: num [1:123] 170 180 220 100 140 100 160 180 220 180 ...16.2.2.2 Sumarização dos dados
Estatísticas descritivas dos escores espirométricos por grupos (tempo) podem ser obtidas com as funções group_by() e summarise() do pacote dplyr:
resumo <- dadosL_uni |>
dplyr::group_by(tempo) |>
dplyr::summarise(n = n(),
média = mean(escores, na.rm =TRUE),
dp = sd(escores, na.rm = TRUE))
resumo# A tibble: 3 × 4
tempo n média dp
<fct> <int> <dbl> <dbl>
1 t0 41 174. 42.8
2 t1 41 205. 53.2
3 t2 41 229. 56.1O resumo mostra que a média aumenta do momento inicial (t0) para o final (t2).
16.2.2.3 Visualização dos dados
Graficamente, pode-se observar os dados através de um conjunto de boxplots (Figura 16.1), usando o pacote ggpubr com a função ggboxplot(). Este gráfico permite visualizar a variação dos escores com o tempo e a variabilidade em cada um dos momentos.
ggpubr::ggboxplot (dadosL_uni,
bxp.errorbar = TRUE,
bxp.errorbar.width = 0.1,
x = "tempo",
y = "escores",
color = "black",
fill = "lightblue",
ylab = "Pico de Fluxo Expiratório (l/min)",
xlab = "Tempo",
outliers = TRUE,
ggtheme = theme_classic(),
legend = "none") +
geom_jitter(
width = 0.15,
size = 1.8,
alpha = 0.6,
color = "darkblue"
) +
theme (text = element_text (size = 12))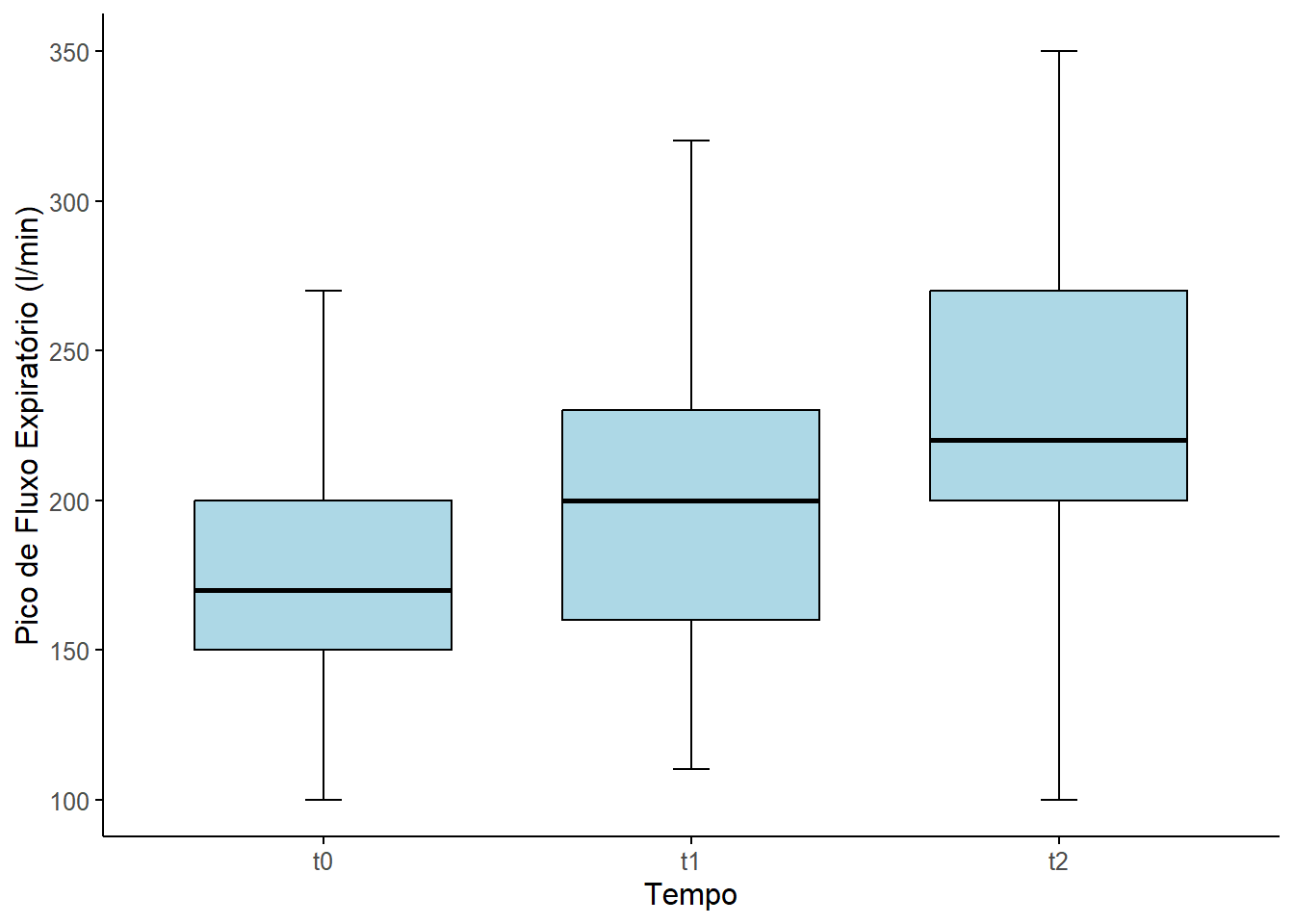
Outra maneira de obter praticamente as mesmas informações visuais é através de um gráfico de linha (Figura 16.2), usando a função geom_beeswarm do pacote ggbeeswarm que mostra bem o comportamento dos escores com o tempo e em cada momento:
ggplot(dadosL_uni, aes(x = tempo, y = escores, group = 1)) +
ggbeeswarm::geom_beeswarm(method = "swarm", color = "cadetblue",cex = 2,
alpha = 0.5, size = 2) +
geom_errorbar(stat = "summary", fun.data = "mean_sd", width = 0.1, linewidth = 0.8) +
geom_point(stat = "summary", fun = "mean", color = "tomato", size = 3) +
geom_line(stat = "summary", fun = "mean", linetype = "dashed") +
labs(y = "Pico de Fluxo Expiratório (l/min)",
x= "Tempo") +
theme_classic()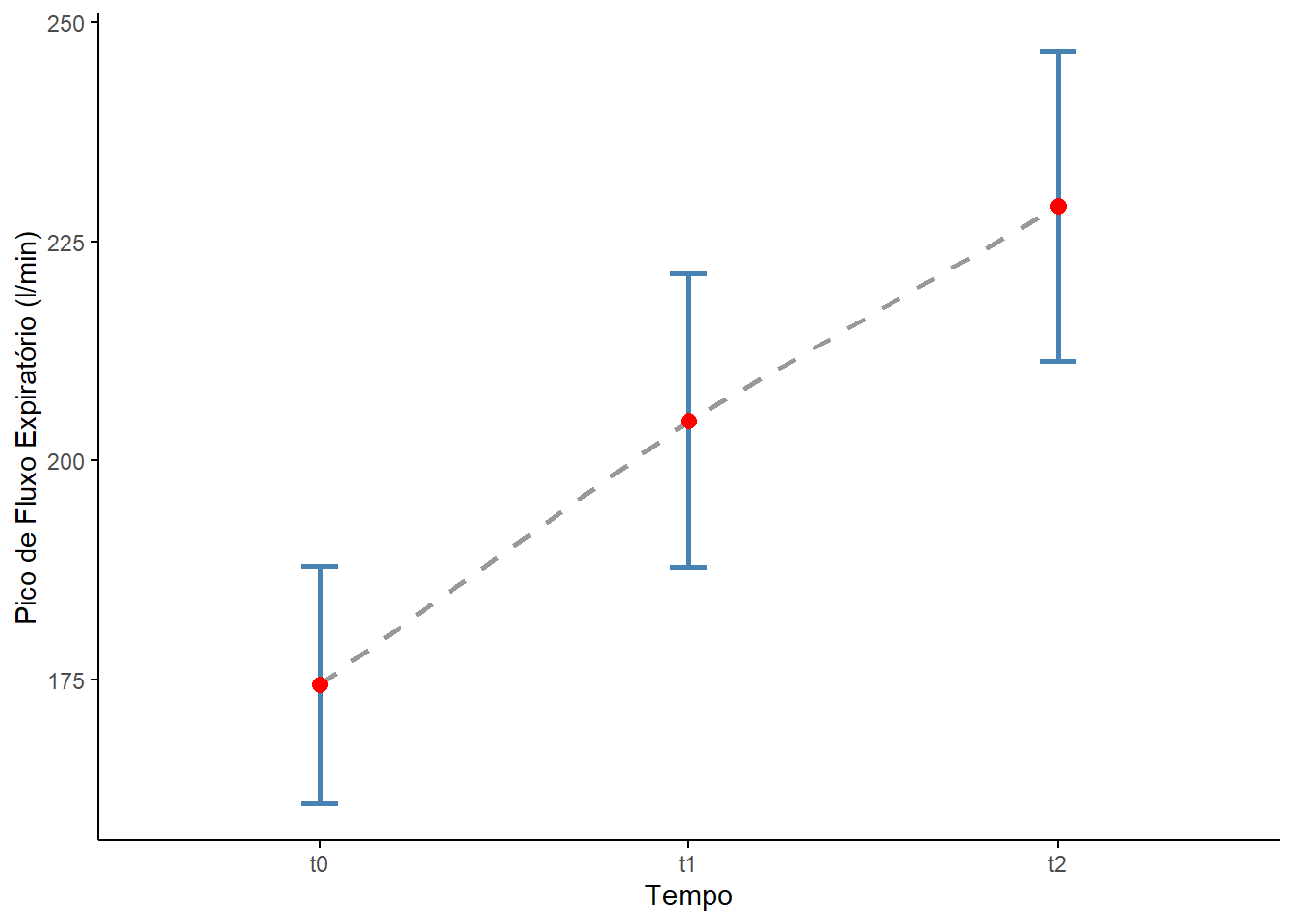
Ambas as figuras exibem uma modificação dos escores espirométricos (melhora nitidamente!) à medida que o tempo passa, utilizando a medicação.
16.2.3 Criação do modelo de ajuste
Para a maioria dos casos, recomenda-se a função aov_ez() do pacote afex (3) que fornece uma abordagem de alta robustez estatística e libera o teste de Mauchly com as correções de esfericidade.
Sintaxe do modelo aov_ez
aov_ez(
id = "sujeito",
dv = "resposta",
data = dataframe,
between = "grupo",
within = "tempo"
)Portanto, no exemplo em estudo, a sintaxe para o ajuste do modelo é:
modelo_ez <- afex::aov_ez(
id = "id",
dv = "escores",
data = dadosL_uni,
within = "tempo"
)Esse comando cria um objeto modelo_ez 2 que contém os resultados da ANOVA de medidas repetidas (tabela da ANOVA do tipo III) e outras informações, como o teste de Mauchly. Para ver a partição da variância e o teste F, usa-se a função summary():
2 Objeto da classe “afex_aov”.
summary(modelo_ez)Warning in summary.Anova.mlm(object$Anova, multivariate = FALSE): HF eps > 1
treated as 1
Univariate Type III Repeated-Measures ANOVA Assuming Sphericity
Sum Sq num Df Error SS den Df F value Pr(>F)
(Intercept) 5052075 1 250720 40 806.011 < 2.2e-16 ***
tempo 61417 2 61853 80 39.718 1.047e-12 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Mauchly Tests for Sphericity
Test statistic p-value
tempo 0.97503 0.6107
Greenhouse-Geisser and Huynh-Feldt Corrections
for Departure from Sphericity
GG eps Pr(>F[GG])
tempo 0.97564 1.879e-12 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
HF eps Pr(>F[HF])
tempo 1.025029 1.047466e-12A saída do modelo mostra a Tabela da ANOVA de Medidas repetidas de um fator (tempo) e resume os resultados do teste de esfericidade de Mauchly e as correções de Greenhouse-Geisser (GG) e Huynh-Feldt (HF) 3.
3 Observe que, no sumário, o HF eps = 1.025029, ou seja, \(> 1\), o que não faz sentido matematicamente, porque o epsilon deve estar no intervalo \(0 \le \epsilon \le 1\). Não existe consequências negativas, inclusive reforça que a suposição de esfericidade foi atendida.
O teste de Mauchly avalia a suposição de esfericidade, que é o pressuposto de que as variâncias das diferenças entre todos os pares de níveis de repetição (os três momentos de medição) são iguais. Como o valor p = 0,6107 não se rejeita a H0 e se conclui que a esfericidade é válida e podemos confiar nos resultados da ANOVA univariada tipo III sem necessidade de correção. As correções de Greenhouse-Geisser e Huynh-Feldt confirmam a forte significância do efeito de tempo , entretanto, embora apresentadas, não são estritamente necessárias neste caso (veja mais sobre esfericidade na Seção 16.2.4.4).
A tabela principal da ANOVA univariada Tipo III, assumindo esfericidade, testa a hipótese nula de que não há diferença entre as médias das medições do PFE nos três momentos de tempo.
O intercepto foi significativo (\(p < 0,001\)), indicando que média geral é significativamente diferente de zero. Este resultado não é importante para o efeito do tratamento.
O efeito do tempo foi significativo (F = 39,72; \(p < 0,001\)), o que significa rejeitar a H0 de igualdade das médias através do tempo.
- O Quadrado Médio(QM) é obtido dividindo a Soma dos Quadrados(SQ) pelos respectivos graus de liberdade (gl) :
\[QM_{tempo} = \frac{SQ_{tempo}}{gl_{tempo}}= \frac{61417}{2}=30708,5\]
\[QM_{erro} = \frac{SQ_{erro}}{gl_{erro}}=\frac{61853}{80}=773,162\]
Logo, F é igual a:
\[F = \frac{QM_{tempo}}{QM_{erro}}=\frac{30708,5}{773,162}=39,718\]
Existe uma diferença estatisticamente significativa nas medições de Peak Flow Meter das crianças asmáticas ao longo dos três momentos distintos (0, 45 e 90 dias). Isto apenas indica que pelo menos dois momentos são diferentes, haverá necessidade de realizar testes post hoc.
Uma outra maneira de obter os resultados do modelo_ez é utilizando o objeto modelo_ez que au ser executado retorna a Tabela da ANOVA, incluindo o tamanho do efeito generalizado (ges):
modelo_ezAnova Table (Type 3 tests)
Response: escores
Effect df MSE F ges p.value
1 tempo 1.95, 78.05 792.47 39.72 *** .164 <.001
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '+' 0.1 ' ' 1
Sphericity correction method: GG 16.2.4 Avaliação dos pressupostos
16.2.4.1 Obtenção dos resíduos
No afex, o $lm é um modelo multivariado: os resíduos são uma matriz com uma coluna por tempo. Para verificar os pressupostos do modelo, é necessário analisar esses resíduos.
residuos <- residuals(modelo_ez$lm)
head(residuos) t0 t1 t2
1 -4.390244 -24.585366 -9.02439
2 -74.390244 -64.585366 -129.02439
3 -14.390244 -24.585366 -9.02439
4 5.609756 -24.585366 20.97561
5 75.609756 95.414634 10.97561
6 5.609756 -4.585366 50.97561Os resíduos estão em formato largo (matriz 41×3). É preciso pivotá-los para longo e depois fazer um left_join pelo id e tempo:
residuos_long <- as.data.frame(residuos) |>
tibble::rownames_to_column("id") |>
tidyr::pivot_longer(cols = c(t0, t1, t2),
names_to = "tempo",
values_to = "residuos") |>
dplyr::mutate(id = factor(id, levels = levels(dadosL_uni$id)))
dadosL_uni <- dplyr::left_join(dadosL_uni, residuos_long, by = c("id", "tempo"))
head(dadosL_uni)# A tibble: 6 × 4
id tempo escores residuos
<fct> <chr> <dbl> <dbl>
1 1 t0 170 -4.39
2 1 t1 180 -24.6
3 1 t2 220 -9.02
4 2 t0 100 -74.4
5 2 t1 140 -64.6
6 2 t2 100 -129. A coluna tempo perdeu a classe fator ao juntar os dadosL_uni com residuos_long e, portanto, precisa ser convertida de volta para fator.
dadosL_uni <- dadosL_uni |>
dplyr::mutate(tempo = factor(tempo))
str(dadosL_uni)tibble [123 × 4] (S3: tbl_df/tbl/data.frame)
$ id : Factor w/ 41 levels "1","2","3","4",..: 1 1 1 2 2 2 3 3 3 4 ...
$ tempo : Factor w/ 3 levels "t0","t1","t2": 1 2 3 1 2 3 1 2 3 1 ...
$ escores : num [1:123] 170 180 220 100 140 100 160 180 220 180 ...
$ residuos: num [1:123] -4.39 -24.59 -9.02 -74.39 -64.59 ...Agora, dadosL_uni tem a coluna residuos com os resíduos do modelo, e tempo volta a ser fator. Essa coluna pode ser usada para avaliar os pressupostos.
16.2.4.2 Avaliação da normalidade
A suposição de normalidade dos resíduos é fundamental para a validade dos testes estatísticos em modelos lineares. Em modelos com medidas repetidas, essa suposição pode variar ao longo dos diferentes momentos de avaliação. Para verificar essa condição, será aplicado o teste de Shapiro-Wilk, usando a função shapiro_test() do pacote rstatix e gerados gráficos QQ dos resíduos por tempo (t0, t1, t2), com o ggplot2.
Como um exercício pedagógico, teste de Shapiro-Wilk será aplicado aos resíduos do modelo e nos dados brutos:
sw_brutos <- dadosL_uni |>
dplyr::group_by(tempo) |>
rstatix::shapiro_test(escores) |>
dplyr::mutate(fonte = "dados brutos")
sw_residuos <- dadosL_uni |>
dplyr::group_by(tempo) |>
rstatix::shapiro_test(residuos) |>
dplyr::mutate(fonte = "resíduos")
dplyr::bind_rows(sw_brutos, sw_residuos) |>
dplyr::select(fonte, tempo, statistic, p) |>
dplyr::arrange(tempo, fonte)# A tibble: 6 × 4
fonte tempo statistic p
<chr> <fct> <dbl> <dbl>
1 dados brutos t0 0.958 0.129
2 resíduos t0 0.958 0.129
3 dados brutos t1 0.950 0.0728
4 resíduos t1 0.950 0.0728
5 dados brutos t2 0.972 0.391
6 resíduos t2 0.972 0.391 Os resultados são idênticos! E isso faz sentido matematicamente. Neste modelo, os resíduos por tempo são simplesmente o resultado de cada escore menos a média do seu tempo.
\[res_{ij}= y_{ij} - \bar{y}_j\]
É uma centralização, e o teste de Shapiro-Wilk é não varia com translações e re-escalamentos — a forma da distribuição não muda. Portanto, testar normalidade nos dados brutos por grupo ou nos resíduos por grupo produz resultados equivalentes neste delineamento.
A diferença entre as duas abordagens só apareceria em modelos mais complexos, como ANCOVA ou ANOVA mista, onde os resíduos removem também o efeito de covariáveis ou fatores entre-sujeitos.
Todos os três momentos não violam normalidade (todos p > 0.05), com t1 sendo o mais próximo do limiar (p = 0.073).
Pode-se observar isso, gerando o QQ plot dos resíduos com o ggplot2, usando o stat_qq() e stat_qq_line(), separado por tempo com facet_wrap():
ggplot(dadosL_uni,
aes(sample = residuos,
color = tempo)) +
stat_qq() +
stat_qq_line() +
facet_wrap(~ tempo) +
labs(
title = "QQ Plot dos Resíduos por Tempo",
x = "Quantis Teóricos",
y = "Quantis Amostrais"
) +
theme_bw() +
theme(legend.position = "none") 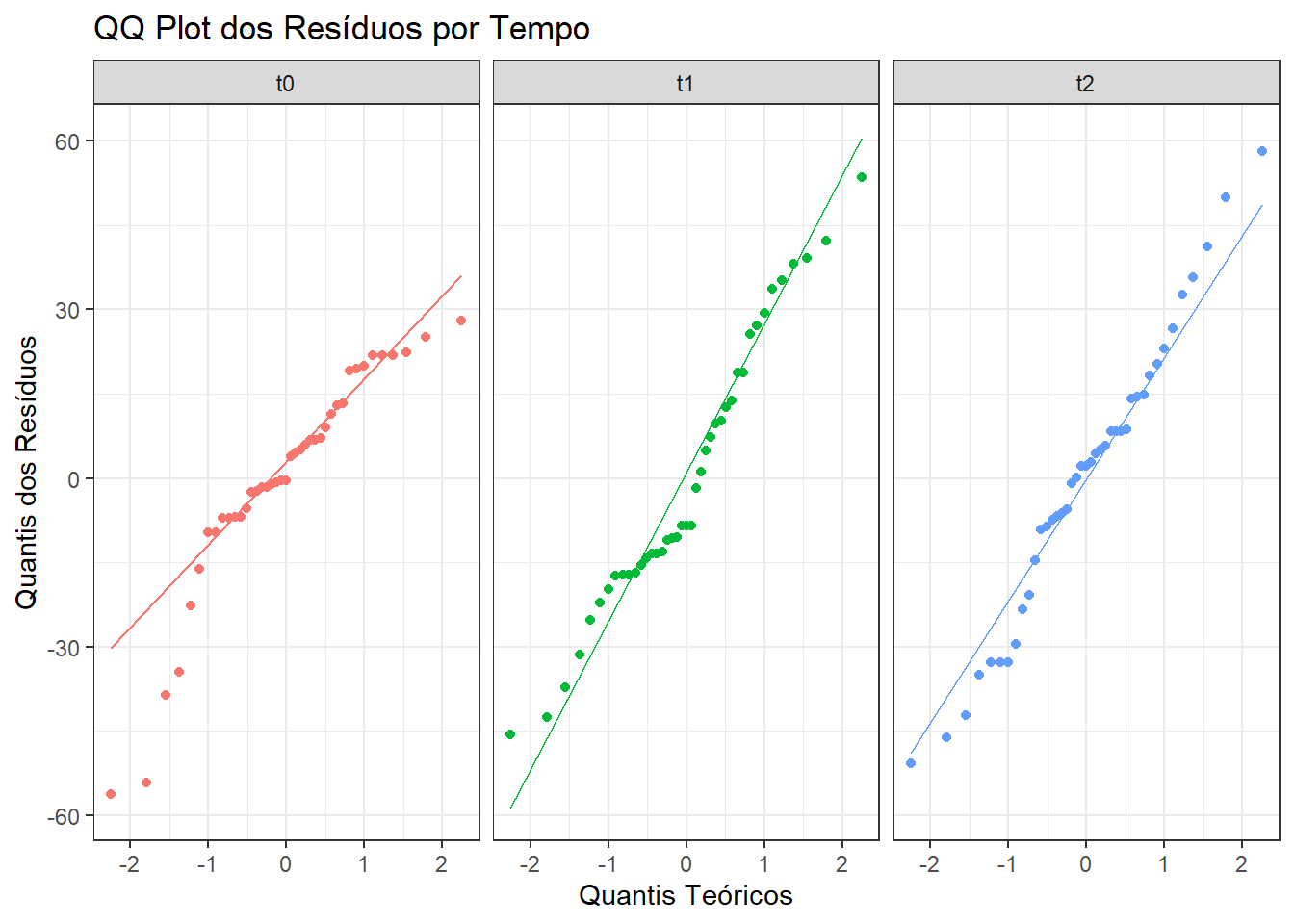
Os três painéis (Figura 16.3) mostram aderência razoável à linha de referência na região central, com algum afastamento nas caudas — padrão consistente com o Shapiro-Wilk (t1 foi o mais próximo do limiar). Os agrupamentos horizontais visíveis nos painéis refletem a natureza discreta do PFE, que é medido em valores inteiros, e não indicam violação de normalidade.
No geral, o pressuposto de normalidade dos resíduos é satisfatório nos três momentos.
16.2.4.3 Identificação de valores atípicos
Não deve haver valores atípicos extremos nos resíduos. Pode-se verificar a presença de valores atípicos, usando a função identify_outliers() do pacote rstatix.
dadosL_uni |>
dplyr::group_by(tempo) |>
rstatix::identify_outliers(residuos)[1] tempo id escores residuos is.outlier is.extreme
<0 linhas> (ou row.names de comprimento 0)Nenhum valor atípico detectado nos resíduos em nenhum dos três momentos. O pressuposto é atendido.
Vale lembrar que identify_outliers() usa o critério do IQR: valores além de \(Q_{1}-1,5\times IQR\) ou \(Q_{3}+1,5\times IQR\) são classificados como atípicos, e além de \(3\times IQR\) como extremos. Apenas os extremos (extreme) costumam ser problemáticos para a ANOVA.
Isso também pode ser verificado na Figura 16.1 dos boxplots.
16.2.4.4 Teste de esfericidade
A esfericidade é a versão da homocedasticidade para medidas repetidas, é avaliada como foi visto (Seção 16.2.3) pelo teste de Mauchly. O teste de Mauchly é uma avaliação da matriz de covariância das diferenças entre os níveis do fator. A matriz de covariância é a ferramenta que avalia se a variação nas mudanças ao longo do tempo é consistente. O teste de Mauchly podes ser obtido ajustando o modelo unifatorial de medidas repetidas (tempo), usando a função aov_ez() do pacote afex.
summary(modelo_ez)$sphericity.testsWarning in summary.Anova.mlm(object$Anova, multivariate = FALSE): HF eps > 1
treated as 1 Test statistic p-value
tempo 0.97503 0.6107A saída do teste de Mauchly exibiu um valor p \(> 0,05\), indicando que o pressuposto da esfericidade não foi violado, não havendo necessidade de recorrer às correções da esfericidade, que seriam obtidas da seguinte maneira:
Lógica do teste de Mauchly
O teste de Mauchly é uma avaliação da matriz de covariância das diferenças entre os níveis do fator. O que isto significa?
O exemplo usado na ANOVA de medidas repetidas corresponde a medida de Pico de Fluxo Expiratório (PFE) em três momentos (t0, t1 e t2, respectivamente, basal, 45 dias e 90 dias).
Para saber se o tratamento funciona, não se está interessado apenas na medida do PFE em cada tempo, mas sim na mudança que o tratamento causou. Se quer saber se a PFE no tempo 1 é diferente da PFE no tempo 0, e se o PFE no tempo 2 é diferente do PFE nos tempos anteriores.
As “mudanças” são as diferenças entre os níveis do fator, ou seja:
- Dif 1: (t1−t0)
- Dif 2: (t2−t0)
- Dif 3: (t2−t1)
A ANOVA de medidas repetidas assume que essas diferenças têm uma relação especial entre si. Ela assume que a variância de cada uma dessas diferenças é aproximadamente a mesma e que a correlação (ou covariância) entre elas também é a mesma.
Matriz de Covariância das Diferenças
Imagine-se que se calculou a variância de cada uma dessas diferenças. A matriz de covariância das diferenças é uma tabela que organiza esses resultados em uma matriz quadrada (3 x 3) e simétrica:

A suposição de esfericidade (que o teste de Mauchly avalia) é que todos os valores nessa matriz devem ser aproximadamente iguais. • As variâncias diagonais devem ser iguais; • As covariâncias fora da diagonal também devem ser iguais.
Importância do Teste de Mauchly
O teste de Mauchly verifica se essa suposição de esfericidade é verdadeira. • Se o teste de Mauchly for não significativo (p > 0,05): Significa que a matriz das diferenças é “esférica” e a suposição de esfericidade foi mantida. Se pode confiar no resultado da ANOVA. • Se o teste de Mauchly for significativo (p < 0,05): Significa que a suposição de esfericidade foi violada. As variâncias das diferenças não são iguais, e isso pode inflar a taxa de erro do Tipo I (a chance de encontrar um resultado significativo quando não existe um de verdade).
Quando a esfericidade é violada, é calculada as correções de Greenhouse-Geisser (GGe) ou Huynh-Feldt (HFe), que ajustam os graus de liberdade e tornam o teste mais conservador, garantindo que o seu resultado final seja confiável. Huynh e Feldt (4) relataram que quando a correção \(\epsilon\) de Greenhouse-Geisser é > 0,75 muitas hipóteses nulas falsas deixam de ser rejeitadas, isto é, o teste é muito conservador, propondo outra correção dos graus de liberdade. É recomendado o uso da correção de Greenhouse-Geisser para o ajuste dos graus de liberdade quando \(\epsilon\) < 0,75 ou nada se sabe a respeito da esfericidade (5). Avaliando o poder destes testes, Muller (6) verificou que a correção de Greenhouse-Geisser fornece um controle adicional do erro Tipo I, enquanto o poder é maximizado.
16.2.4.5 Resumo da avaliação dos pressupostos
Todos os pressupostos foram atendidos. Vale notar que o QQ plot mostra leve afastamento nas caudas — os dados têm uma distribuição um pouco mais achatada que a normal — mas o Shapiro-Wilk não detectou violação significativa em nenhum dos três momentos, e com n=41 a ANOVA de medidas repetidas é razoavelmente robusta a pequenos desvios de normalidade.
16.2.5 Análise post hoc
A ANOVA de medidas repetidas indicou uma modificação significativa nos escores de PEF ao longo do tempo com o uso da medicação. No entanto, esse teste apenas revela que há diferenças entre os tempos, sem especificar entre quais pares de momentos essas diferenças ocorrem. Para identificar onde essas diferenças são estatisticamente significativas, é necessário realizar uma análise post hoc.
16.2.5.1 Médias marginais estimadas por tempo
emm <- emmeans(modelo_ez, ~ tempo)
emm tempo emmean SE df lower.CL upper.CL
t0 174 6.69 40 161 188
t1 205 8.31 40 188 221
t2 229 8.76 40 211 247
Confidence level used: 0.95 16.2.5.2 Comparações pareadas com correção de Bonferroni
Optou-se pelo método de Bonferroni por ser mais conservador e reduzir o risco de falsos positivos, mesmo que sacrifique o poder estatístico. Em contextos com muitos grupos, métodos como Holm ou Benjamini-Hochberg (BH) podem ser preferidos por sua maior sensibilidade.
pairs(emm, adjust = "bonferroni") contrast estimate SE df t.ratio p.value
t0 - t1 -30.2 5.84 40 -5.168 <.0001
t0 - t2 -54.6 5.95 40 -9.185 <.0001
t1 - t2 -24.4 6.61 40 -3.700 0.0019
P value adjustment: bonferroni method for 3 tests Todos os três pares diferem significativamente após correção de Bonferroni:
pairs(emm, adjust = "bonferroni") |>
as.data.frame() |>
dplyr::mutate(
contrast = c("t0 vs t1", "t0 vs t2", "t1 vs t2"),
estimate = round(estimate, 1),
SE = round(SE, 2),
t.ratio = round(t.ratio, 3),
p.value = dplyr::case_when(
p.value < 0.001 ~ "< 0,001",
TRUE ~ format(round(p.value, 3), nsmall = 3)
)
) |>
dplyr::select(contrast, estimate, SE, df, t.ratio, p.value) |>
flextable() |>
set_header_labels(
contrast = "Contraste",
estimate = "Diferença (l/min)",
SE = "EP",
df = "gl",
t.ratio = "t",
p.value = "p"
) |>
theme_booktabs() |>
align(align = "center", part = "all") |>
align(j = 1, align = "left", part = "all") |>
bold(part = "header") |>
width(j = 1, width = 2) |>
width(j = 2:6, width = 1.2) |>
add_footer_lines("Correção de Bonferroni; EP = erro padrão; gl = graus de liberdade.")Contraste | Diferença (l/min) | EP | gl | t | p |
|---|---|---|---|---|---|
t0 vs t1 | -30.2 | 5.84 | 40 | -5.168 | < 0,001 |
t0 vs t2 | -54.6 | 5.95 | 40 | -9.185 | < 0,001 |
t1 vs t2 | -24.4 | 6.61 | 40 | -3.700 | 0.002 |
Correção de Bonferroni; EP = erro padrão; gl = graus de liberdade. | |||||
O PFE aumentou progressivamente em todos os momentos — a melhora de t0 para t2 foi a maior (~55 l/min), e mesmo entre t1 e t2 houve ganho adicional significativo, sugerindo que o efeito do corticoide continuou se acumulando ao longo dos 90 dias.
16.2.6 Tamanho do Efeito Padronizado
O tamanho do efeito é uma medida da magnitude da diferença entre grupos, independente do tamanho da amostra. O tamanho do efeito na ANOVA pode ser obtido usando o parâmetro \(\eta^2\) (eta ao quadrado), parcial ou generalizado, que está disponível no pacote afex, usado para ajustar o modelo (Seção 16.2.3). Na ANOVA de medidas repetidas, é calculado o eta ao quadrado generalizado, pois o parcial pode superestimar o efeito. O eta ao quadrado generalizado mede a proporção da variância explicada por um fator em relação a variância total. Usando o modelo_ez, o tamanho do efeito pode ser obtido da seguinte forma usando a função eta_squared() do pacote effectsize:
eta_g <- effectsize::eta_squared (modelo_ez, generalized = TRUE)
effectsize::interpret_eta_squared(eta_g)# Effect Size for ANOVA (Type III)
Parameter | Eta2 (generalized) | 95% CI | Interpretation
--------------------------------------------------------------
tempo | 0.16 | [0.05, 1.00] | large
- Observed variables: All
- One-sided CIs: upper bound fixed at [1.00].
- Interpretation rule: field2013\(\eta^2_{G} = 0,16\), considerado efeito grande pelos critérios de Cohen (pequeno ≥ 0,01; médio ≥ 0,06; grande ≥ 0,14). Esse valor coincide com o ges já reportado na tabela do afex, mas agora com a incerteza quantificada.
eta_g |> as.data.frame() Parameter Eta2_generalized CI CI_low CI_high
1 tempo 0.1642203 0.95 0.04985749 1anova(modelo_ez) |>
as.data.frame() |>
tibble::rownames_to_column("Efeito") |>
dplyr::mutate(
gl = paste0(round(`num Df`, 2), ", ", round(`den Df`, 2)),
MSE = round(MSE, 2),
F = round(F, 3),
eta2G = round(eta_g$Eta2_generalized, 3),
IC95 = paste0("[", round(eta_g$CI_low, 2), ", 1.00]"),
p.value = ifelse(`Pr(>F)` < 0.001, "< 0,001", round(`Pr(>F)`, 3))
) |>
dplyr::select(Efeito, gl, MSE, F, eta2G, IC95, p.value) |>
flextable() |>
set_header_labels(
Efeito = "Efeito",
gl = "gl (GG)",
MSE = "QME",
F = "F",
eta2G = "\u03b7\u00b2G",
IC95 = "IC 95%",
p.value = "p"
) |>
theme_booktabs() |>
align(align = "center", part = "all") |>
align(j = 1, align = "left", part = "all") |>
bold(part = "header") |>
width(j = 1, width = 1.5) |>
width(j = 2, width = 1.8) |>
width(j = 3:7, width = 1.1) |>
add_footer_lines("QME = quadrado médio do erro; η²G = eta quadrado generalizado; IC = intervalo de confiança.")Efeito | gl (GG) | QME | F | η²G | IC 95% | p |
|---|---|---|---|---|---|---|
tempo | 1.95, 78.05 | 792.47 | 39.718 | 0.164 | [0.05, 1.00] | < 0,001 |
QME = quadrado médio do erro; η²G = eta quadrado generalizado; IC = intervalo de confiança. | ||||||
16.2.7 Resultado Final
A Tabela 16.4 mostra os resultados finais da Anova de Medidas Repetidas:
# --- ANOVA ---
anova_row <- anova(modelo_ez) |>
as.data.frame() |>
tibble::rownames_to_column("label") |>
dplyr::transmute(
label = label,
gl = paste0(round(`num Df`, 2), "; ", round(`den Df`, 2)),
stat2 = format(round(MSE, 2), nsmall = 2, big.mark = "."),
stat3 = format(round(F, 2), nsmall = 2),
efeito = paste0("η²G = ", round(eta_g$Eta2_generalized, 2)),
ic = paste0("[", round(eta_g$CI_low, 2), "; 1,00]"),
p = "< 0,001"
)
# --- Post-hoc ---
ph_df <- pairs(emm, adjust = "bonferroni") |> as.data.frame()
d_rm_t0_t1 <- effectsize::repeated_measures_d(dados_uni$t1, dados_uni$t0, method = "rm")
d_rm_t0_t2 <- effectsize::repeated_measures_d(dados_uni$t2, dados_uni$t0, method = "rm")
d_rm_t1_t2 <- effectsize::repeated_measures_d(dados_uni$t2, dados_uni$t1, method = "rm")
drm_list <- list(as.data.frame(d_rm_t0_t1),
as.data.frame(d_rm_t0_t2),
as.data.frame(d_rm_t1_t2))
ph_rows <- data.frame(
label = c("t0 vs t1", "t0 vs t2", "t1 vs t2"),
gl = as.character(ph_df$df),
stat2 = format(round(ph_df$SE, 2), nsmall = 2),
stat3 = format(round(ph_df$t.ratio, 2), nsmall = 2),
efeito = paste0("d_rm = ", sapply(drm_list, \(x) format(round(x$d_rm, 2), nsmall = 2))),
ic = sapply(drm_list, \(x) paste0("[", round(x$CI_low, 2), "; ", round(x$CI_high, 2), "]")),
p = dplyr::case_when(
ph_df$p.value < 0.001 ~ "< 0,001",
TRUE ~ format(round(ph_df$p.value, 3), nsmall = 3)
)
)
# --- Título das seções ---
blank <- data.frame(label="", gl="", stat2="", stat3="", efeito="", ic="", p="")
sec1 <- blank |> dplyr::mutate(label = "ANOVA")
sec2 <- blank |> dplyr::mutate(label = "Comparações post-hoc (Bonferroni)")
# --- Combinar no df final ---
df_final <- dplyr::bind_rows(sec1, anova_row, sec2, ph_rows)
sec_rows <- c(1, 3)
# --- Flextable ---
df_final |>
flextable() |>
set_header_labels(
label = "Fonte / Contraste",
gl = "gl",
stat2 = "QME / EP",
stat3 = "F / t",
efeito = "Tamanho de efeito",
ic = "IC 95%",
p = "p"
) |>
theme_booktabs() |>
merge_h(i = sec_rows, part = "body") |>
bold(i = sec_rows, part = "body") |>
bg(i = sec_rows, bg = "#eeeeee", part = "body") |>
align(align = "center", part = "all") |>
align(j = 1, align = "left", part = "all") |>
bold(part = "header") |>
width(j = 1, width = 2.2) |>
width(j = 2:7, width = 1.1) |>
add_footer_lines("gl = graus de liberdade com correção de Greenhouse-Geisser (ANOVA) ou graus de liberdade do denominador (post-hoc); QME = quadrado médio do erro; EP = erro padrão; η²G = eta quadrado generalizado; d_rm = Cohen's d para medidas repetidas; IC = intervalo de confiança de 95%.")Fonte / Contraste | gl | QME / EP | F / t | Tamanho de efeito | IC 95% | p |
|---|---|---|---|---|---|---|
ANOVA | ||||||
tempo | 1.95; 78.05 | 792.47 | 39.72 | η²G = 0.16 | [0.05; 1,00] | < 0,001 |
Comparações post-hoc (Bonferroni) | ||||||
t0 vs t1 | 40 | 5.84 | -5.17 | d_rm = 0.60 | [0.35; 0.84] | < 0,001 |
t0 vs t2 | 40 | 5.95 | -9.19 | d_rm = 1.02 | [0.75; 1.3] | < 0,001 |
t1 vs t2 | 40 | 6.61 | -3.70 | d_rm = 0.44 | [0.19; 0.68] | 0.002 |
gl = graus de liberdade com correção de Greenhouse-Geisser (ANOVA) ou graus de liberdade do denominador (post-hoc); QME = quadrado médio do erro; EP = erro padrão; η²G = eta quadrado generalizado; d_rm = Cohen's d para medidas repetidas; IC = intervalo de confiança de 95%. | ||||||
16.2.8 Gráfico final
emm_df <- as.data.frame(emm)
pval_df <- data.frame(
group1 = c("t0", "t1", "t0"),
group2 = c("t1", "t2", "t2"),
label = c("***", "**", "***"),
y.position = c(255, 263, 273)
)
ggplot(emm_df, aes(x = tempo, y = emmean, group = 1)) +
geom_line(linetype = "dashed", linewidth = 0.7) +
geom_errorbar(aes(ymin = lower.CL, ymax = upper.CL),
width = 0.08, linewidth = 0.8) +
geom_point(size = 3.5) +
ggpubr::stat_pvalue_manual(pval_df,
label = "label",
tip.length = 0.01,
bracket.size = 0.5) +
scale_x_discrete(labels = c(t0 = "Basal (0 dias)",
t1 = "45 dias",
t2 = "90 dias")) +
scale_y_continuous(limits = c(155, 285)) +
labs(x = "Momento de avaliação",
y = "Pico de Fluxo Expiratório (l/min)",
caption = "Médias marginais estimadas com IC 95%; correção de Bonferroni: ** p < 0,01; *** p < 0,001") +
theme_classic(base_size = 13)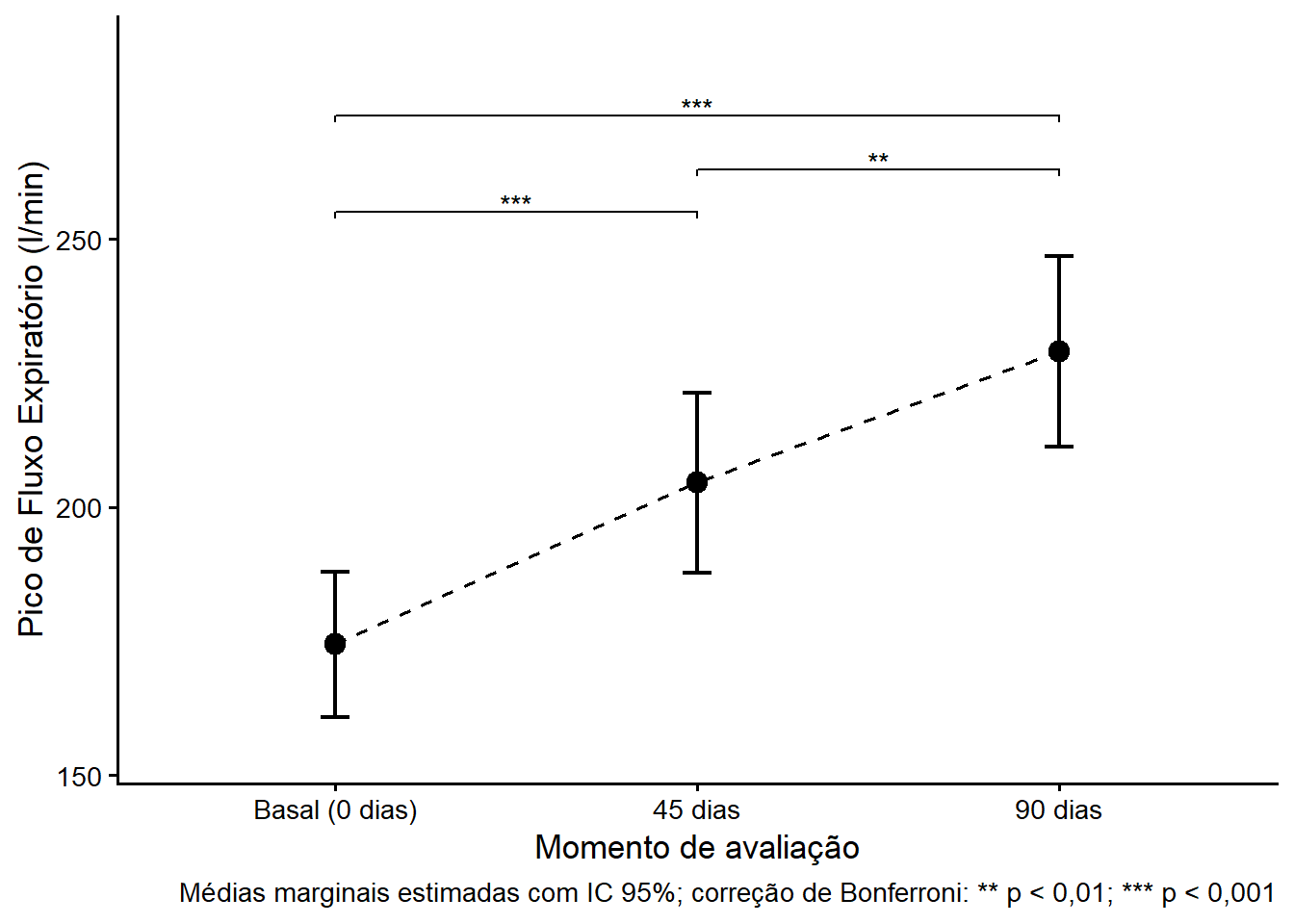
16.2.9 Conclusão
A ANOVA de medidas repetidas revelou efeito significativo do tempo sobre o pico de fluxo expiratório [F(1,95; 78,05) = 39,72; p < 0,001; η²G = 0,16; IC 95%: 0,05–1,00], indicando que os escores espirométricos variaram ao longo dos três momentos de avaliação. O teste de esfericidade de Mauchly não foi significativo (W = 0,975; p = 0,611), embora a correção de Greenhouse–Geisser tenha sido aplicada por padrão. As comparações post-hoc com correção de Bonferroni demonstraram diferenças significativas entre todos os pares de momentos. O PFE médio estimado aumentou de 174 l/min (IC 95%: 161–188) no momento basal para 205 l/min (IC 95%: 188–221) aos 45 dias (Δ = 30,2 l/min; t(40) = 5,17; p < 0,001; drm = 0,60; IC 95%: 0,35–0,84) e para 229 l/min (IC 95%: 211–247) aos 90 dias (Δ = 54,6 l/min; t(40) = 9,19; p < 0,001; drm = 1,02; IC 95%: 0,75–1,30). A comparação entre os momentos de 45 e 90 dias também revelou diferença significativa (Δ = 24,4 l/min; t(40) = 3,70; p = 0,002; drm = 0,44; IC 95%: 0,19–0,68), indicando que a melhora da função pulmonar continuou ao longo do segundo mês de tratamento. A evolução das médias marginais estimadas com os respectivos intervalos de confiança de 95% está ilustrada na Figura 20.9.
O η²G = 0,16 corresponde a um efeito grande pelos critérios de Cohen (≥ 0,14), e os drm variam de moderado (0,44 para t1 vs t2) a grande (1,02 para t0 vs t2), evidenciando relevância clínica consistente em todas as comparações.
16.3 ANOVA Mista
A ANOVA Mista é um tipo de análise de variância usada quando o estudo envolve simultaneamente um fator entre‑sujeitos (grupos diferentes de participantes) e um fator intra‑sujeitos (medidas repetidas nos mesmos participantes). Ela permite avaliar diferenças nas médias da variável dependente tanto entre os grupos quanto ao longo do tempo ou condições, além de verificar se a evolução dos grupos ao longo do tempo é diferente.
O ponto central da ANOVA Mista é a interação entre os fatores. Uma interação significativa indica que o efeito do tempo (ou condição repetida) depende do grupo, ou que os grupos se comportam de maneira diferente ao longo das medições. Quando a interação é significativa, ela deve ser priorizada na interpretação, pois os efeitos principais isolados podem não refletir adequadamente o padrão real dos dados.
16.3.1 Dados usados no exemplo
Os dados que servirão de exemplo são os mesmos da Seção 16.2.2 sem usar o filtro para os 41 casos que correspondem às crianças de 5 a 15 anos que receberam um novo corticoide inalatório. Os controles são 41 crianças da mesma idade que receberam o tratamento habitual (Figura 16.5).

dados_mista <- readxl::read_excel("dados/dadosAsma.xlsx")
str(dados_mista)tibble [82 × 5] (S3: tbl_df/tbl/data.frame)
$ id : num [1:82] 1 2 3 4 5 6 7 8 9 10 ...
$ grupo: chr [1:82] "caso" "caso" "caso" "caso" ...
$ t0 : num [1:82] 170 100 160 180 250 180 170 180 240 200 ...
$ t1 : num [1:82] 180 140 180 180 300 200 180 200 320 200 ...
$ t2 : num [1:82] 220 100 220 250 240 280 220 250 350 250 ...Assim, como realizado com a ANOVA de medidas repetidas de um fator, os dados serão transformados para o formato longo e atribuídos a um objeto denominado dadosL_mista:
dadosL_mista <- dados_mista |>
tidyr::pivot_longer(cols = c(t0, t1, t2),
names_to = "tempo",
values_to = "escores") |>
convert_as_factor(id, grupo, tempo)
dadosL_mista |> sample_n_by(grupo, tempo, size = 1)# A tibble: 6 × 4
id grupo tempo escores
<fct> <fct> <fct> <dbl>
1 33 caso t0 130
2 17 caso t1 220
3 22 caso t2 250
4 78 controle t0 200
5 65 controle t1 220
6 63 controle t2 20016.3.1.1 Sumarização dos dados
Os dados serão sumarizados por grupo e tempo e, em seguida, serão calculadas algumas estatísticas resumidas da variável de escore: média e sd (desvio padrão). Isso será realizado através das funções group_by() e get_summary_stats() do pacote rstatix.
dadosL_mista |>
rstatix::group_by(grupo, tempo) |>
rstatix::get_summary_stats(escores, type = "mean_sd")# A tibble: 6 × 6
grupo tempo variable n mean sd
<fct> <fct> <fct> <dbl> <dbl> <dbl>
1 caso t0 escores 41 174. 42.8
2 caso t1 escores 41 205. 53.2
3 caso t2 escores 41 229. 56.1
4 controle t0 escores 41 184. 43.6
5 controle t1 escores 41 192. 37.5
6 controle t2 escores 41 212. 40.916.3.1.2 Visualização dos dados
Pode-se observar os dados de diversas maneiras. Para ANOVA medidas repetidas de dois fatores, o gráfico de linha com barra de erro é bastante útil, pois além de permitir a visualização dos dados através do tempo, pode-se ver a existência ou não de interação entre os fatores. Para criar a (Figura 16.6) serão usadas as funções ggline() do pacote ggpubr.
ggpubr::ggline(dadosL_mista,
x = "tempo",
y = "escores",
color = "grupo",
palette = "d3",
linewidth = 0.7,
linetype = "dashed",
add = "mean_ci",
error.plot = "errorbar",
position = position_dodge(width = 0.3),
point.size = 1.5,
ylab = "Pico de Fluxo Expiratório (l/min)",
xlab = "Momento",
legend = "top",
ggtheme = theme_classic()) +
scale_x_discrete(limits = c("t0", "t1", "t2"),
labels = c("Basal", "45 dias", "90 dias")) +
labs(color = NULL)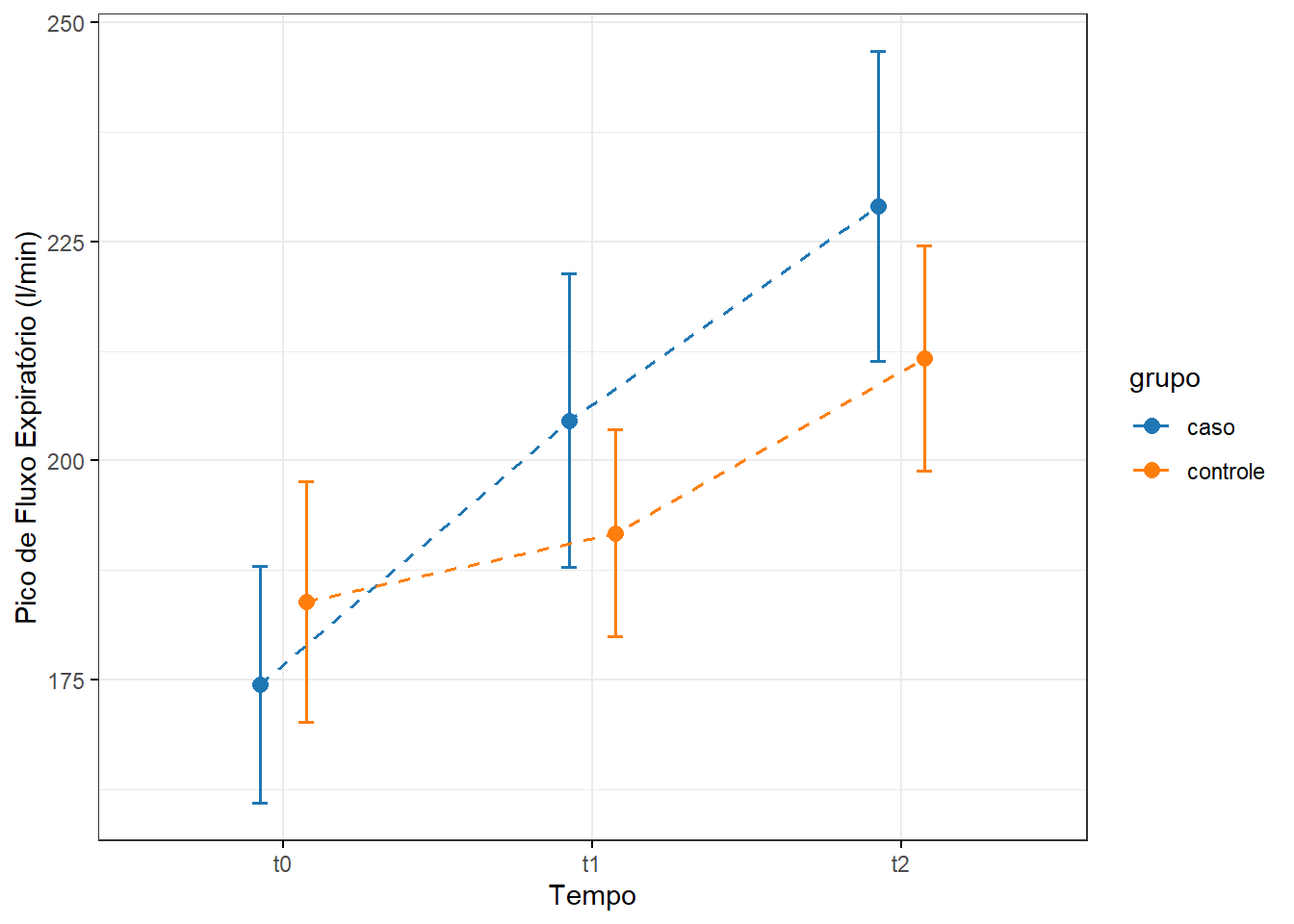
A observação da Figura 16.6 mostra que ambos os grupos melhoraram a função respiratória com o tempo. O grupo caso teve uma melhora mais acentuada, o que pode indicar que a intervenção foi eficaz. O grupo controle manteve uma evolução positiva estável. A análise estatística (como ANOVA de medidas repetidas) poderia confirmar se essas diferenças são significativas ou apenas tendências visuais.
16.3.2 Criação do modelo misto
Este modelo permite testar se há diferença no tempo, independentemente do grupo; testar se há diferença entre os grupos, independentemente do tempo e verificar se há interação entre tempo e grupo, ou seja, se a mudança ao longo do tempo difere entre os grupos (por ex., se o tratamento teve efeito). Usando o formato longo, pode-se fazer o ajuste do modelo com a função aov_ez() do pacote afex. Essa função também é apropriada para delineamentos com mais de um fatores: um fator intra-sujeitos (tempo); um fator entre sujeitos (grupo) e, principalmente, se houver interação, desbalanceamento e se deseja realizar uma ANOVA tipo III. Além disso, a aov_ez já calcula automaticamente o teste de esfericidade de Mauchly e as correções (Greenhouse-Geisser e Huynh-Feldt).
Veja a sintaxe da função em Seção 16.2.3.
modelo_ez2 <- afex::aov_ez(id = "id",
data = dadosL_mista,
dv = "escores",
between = "grupo",
within = "tempo")Contrasts set to contr.sum for the following variables: gruposummary(modelo_ez2)
Univariate Type III Repeated-Measures ANOVA Assuming Sphericity
Sum Sq num Df Error SS den Df F value Pr(>F)
(Intercept) 9763350 1 430255 80 1815.3608 < 2.2e-16 ***
grupo 2923 1 430255 80 0.5435 0.463132
tempo 69803 2 81254 160 68.7251 < 2.2e-16 ***
grupo:tempo 8479 2 81254 160 8.3482 0.000356 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Mauchly Tests for Sphericity
Test statistic p-value
tempo 0.95941 0.19459
grupo:tempo 0.95941 0.19459
Greenhouse-Geisser and Huynh-Feldt Corrections
for Departure from Sphericity
GG eps Pr(>F[GG])
tempo 0.96099 < 2.2e-16 ***
grupo:tempo 0.96099 0.0004365 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
HF eps Pr(>F[HF])
tempo 0.984147 5.875378e-22
grupo:tempo 0.984147 3.867194e-04O teste de Mauchly não foi significativo para tempo e para a interação grupo:tempo (p = 0,195), indicando que o pressuposto de esfericidade não foi violado. As correções de Greenhouse-Geisser (\(\epsilon = 0,961\)) e Huynh-Feldt (\(\epsilon = 0,984\)) confirmam resultados praticamente idênticos.
Efeito principal de grupo não foi significativo (p = 0,463). Em média, os grupos caso e controle (n = 41 cada) não diferem nos escores quando se ignora o fator tempo.
Efeito principal de tempo foi significativo (p < 0,001). Os escores variam ao longo dos três momentos (t0, t1, t2) independentemente do grupo.
Interação grupo × tempo foi significativa (p < 0,001). Este é o resultado mais importante — a trajetória de mudança ao longo do tempo é diferente entre os grupos. Ou seja, o efeito do tempo depende do grupo (ou vice-versa).
Como a interação é significativa (Figura 16.6), os efeitos principais devem ser interpretados com cautela. O próximo passo natural é examinar os efeitos simples (simple effects) — comparar os grupos em cada momento separadamente, ou comparar os momentos dentro de cada grupo — para entender o padrão da interação.
16.3.3 Avaliação dos pressupostos do modelo
16.3.3.1 Esfericidade
O Teste de Mauchly, obtido junto com o modelo, mostrou que tanto o tempo como a interação grupo:tempo têm valores p > 0,05. Não houve violação da esfericidade. Como visto, as correções de GG e HF são semelhantes, mas elas são desnecessárias quando não há violação da esfericidade.
Da mesma maneira que na ANOVA de Medidas Repetidas de uma via, pode também obter o teste de Mauchly com o seguinte código:
summary(modelo_ez2)$sphericity.tests Test statistic p-value
tempo 0.95941 0.19459
grupo:tempo 0.95941 0.1945916.3.3.2 Obtenção dos resíduos
Os resíduos podem ser obtidos da seguinte maneira, utilizando o modelo_ez :
dadosL_mista$residuos <- residuals(modelo_ez2)Isto cria uma coluna denominada residuos (diferença entre os valores observados e os ajustados) e que deve ser usada na análise dos pressupostos.
16.3.3.3 Avaliação da normalidade dos resíduos
A verificação recomendada é por grupo e tempo, pois o pressuposto de normalidade na ANOVA diz respeito à distribuição dos erros dentro de cada célula do delineamento — ou seja, dentro de cada combinação de grupo × tempo. Verificar os resíduos totais agrega células diferentes numa distribuição única, o que pode mascarar violações localizadas (ex.: não-normalidade só no grupo caso no momento t1). Agregar todos os resíduos numa única distribuição confunde a variação sistemática entre células com a variação aleatória intra-célula, podendo tanto mascarar violações reais quanto criar falsos alarmes (7); (8)].
Uma consideração prática importante: com n = 41 por célula, o Teorema Central do Limite já oferece proteção considerável — mesmo que Shapiro indique algum desvio leve da normalidade, a ANOVA tende a ser robusta (7); (9)]. O que realmente importa é identificar violações graves (ex.: distribuição fortemente assimétrica ou com outliers extremos) em alguma célula específica.
dadosL_mista |>
dplyr::group_by(grupo, tempo) |>
rstatix::shapiro_test(residuos)# A tibble: 6 × 5
grupo tempo variable statistic p
<fct> <fct> <chr> <dbl> <dbl>
1 caso t0 residuos 0.945 0.0468
2 caso t1 residuos 0.960 0.154
3 caso t2 residuos 0.961 0.167
4 controle t0 residuos 0.945 0.0484
5 controle t1 residuos 0.961 0.172
6 controle t2 residuos 0.943 0.0414Os três momentos apresentam p < 0,05, estatisticamente significativas, mas leves. Dois elementos sustentam essa afirmação:
- W (estatística do teste) próximo de 1(0,943 a 0,045) - indica desvio pequeno da normalidade, não uma distribuição radicalmente assimétrica;
- valores p limítrofes (0,041 - 0,048) - pequeno afastamento do limiar \(\alpha = 0,05\), sugerindo que a significância pode ser artefato da sensibilidade do teste com esse n.
Recomenda-se complementar com QQ plots para inspecionar visualmente:
dadosL_mista |>
ggplot(aes(sample = residuos,
color = tempo)) +
stat_qq() +
stat_qq_line() +
facet_grid(grupo ~ tempo) +
labs(x = "Quantis teóricos",
y = "Quantis observados") +
theme_bw() +
theme(legend.position = "none") 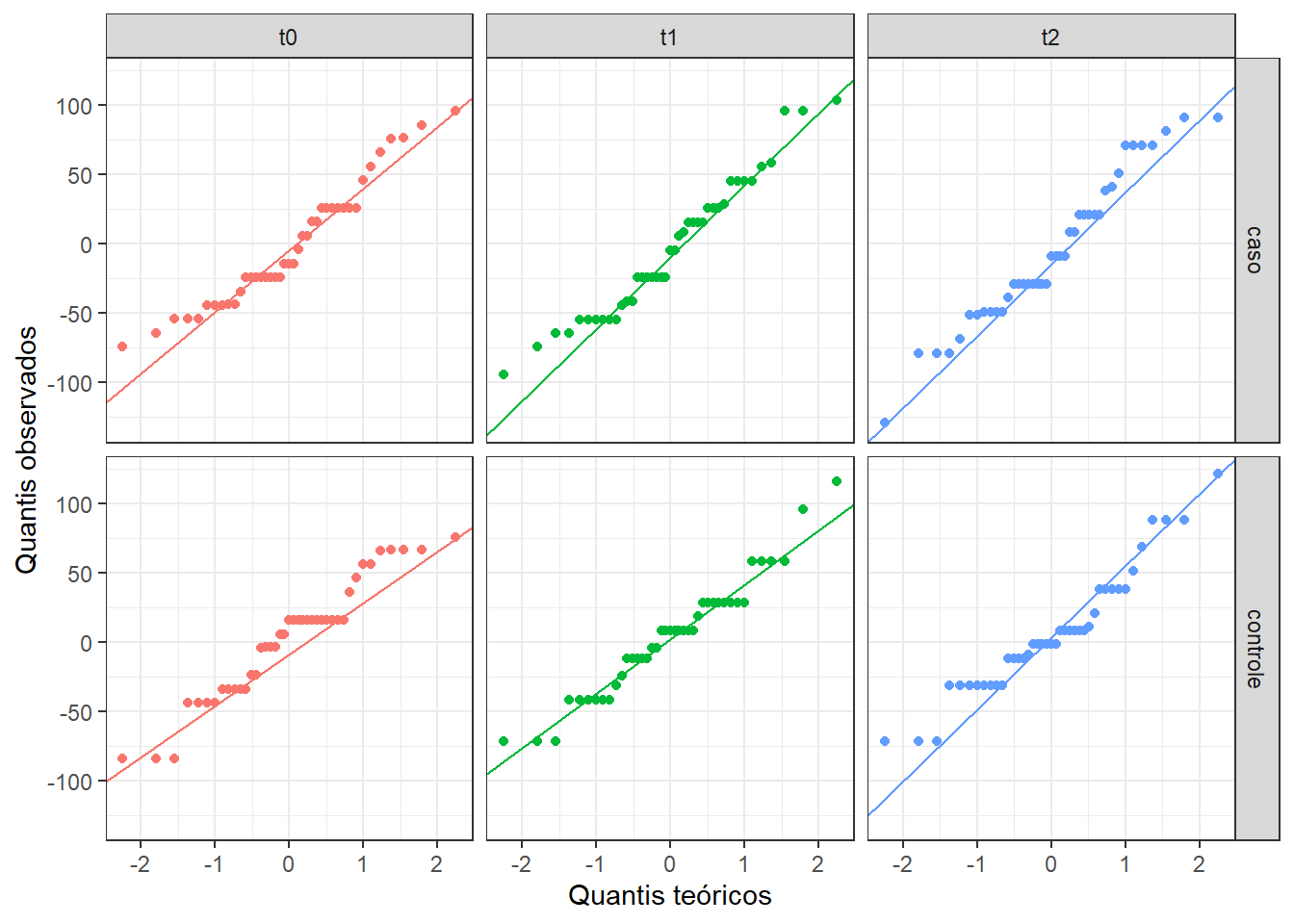
Como os W ficaram entre 0,943 e 0,961, espera-se ver pontos majoritariamente na reta, com pequenos desvios nas caudas — o que é consistente com violação leve, não grave (Tabela 16.5).
Padrão no gráfico | Interpretação |
|---|---|
Pontos na reta | Normalidade atendida |
Curva em "S" | Distribuição com caudas mais pesadas (heavy tails) |
Pontos acima da reta nas extremidades | Assimetria positiva (cauda à direita) |
Pontos abaixo da reta nas extremidades | Assimetria negativa (cauda à esquerda) |
Pontos isolados nas extremidades | Outliers |
16.3.3.4 Pesquisa de outliers nos residuos
A presença de outliers serão analisados, usando função identify_outliers() do pacote rstatix.
dadosL_mista |>
dplyr::group_by(grupo, tempo) |>
rstatix::identify_outliers(residuos)# A tibble: 1 × 7
grupo tempo id escores residuos is.outlier is.extreme
<fct> <fct> <fct> <dbl> <dbl> <lgl> <lgl>
1 controle t1 82 120 115. TRUE FALSE O outlier está em uma célula sem violação de normalidade O participante id = 82 (controle t1) aparece numa célula com W = 0,961 e p = 0,172 — que não havia sinalizado problema no Shapiro-Wilk.
É um outlier leve, não extremo is.extreme = FALSE indica que o valor está entre \(1,5 \times IIQ\) e \(3 \times IIQ\) dos quartis — o critério do boxplot para outlier leve. Não ultrapassa o limiar de outlier extremo (> 3×IIQ), que seria mais preocupante.
O resíduo de ~115 é expressivo em termos absolutos, mas com n = 41 na célula e sem classificação como extremo, a ANOVA mista permanece válida. Poderia-se investigar o id = 82 nos dados originais para verificar se é um erro de entrada ou um valor genuíno. Como é plausível, deve-se mantê-lo na análise e reportar a sua existência.
16.3.3.5 Homogeneidade de variâncias (fator entre-sujeitos)
Como o fator grupo é entre-sujeitos, o modelo assume que a variância dos escores é igual entre os grupos em cada momento. Verifica-se com o teste de Levene:
dadosL_mista |>
dplyr::group_by(tempo) |>
rstatix::levene_test(escores ~ grupo)# A tibble: 3 × 5
tempo df1 df2 statistic p
<fct> <int> <int> <dbl> <dbl>
1 t0 1 80 0.00639 0.936
2 t1 1 80 4.37 0.0397
3 t2 1 80 4.71 0.0330Será realizada uma verificação da razão das variâncias entre grupos por tempo:
dadosL_mista |>
dplyr::group_by(grupo, tempo) |>
dplyr::summarise(variancia = round(var(escores), 1),
.groups = "drop") |>
tidyr::pivot_wider(names_from = grupo, values_from = variancia) |>
dplyr::mutate(razao = round(caso / controle, 2))# A tibble: 3 × 4
tempo caso controle razao
<fct> <dbl> <dbl> <dbl>
1 t0 1835. 1899. 0.97
2 t1 2830 1404. 2.01
3 t2 3149 1670. 1.89Há violação em t1 e t2, mas o contexto atenua a preocupação. A variância do grupo caso é aproximadamente o dobro da do grupo controle nesses momentos (razões de ~2:1), enquanto t0 está praticamente idêntico (0,97).
Por que os resultados da ANOVA permanecem confiáveis?
O fator determinante aqui é o equilíbrio do delineamento — grupos com n igual (41 × 41). Com tamanhos amostrais iguais, o teste F da ANOVA é reconhecidamente robusto a violações moderadas da homogeneidade de variâncias: a taxa de erro Tipo I se mantém próxima ao \(\alpha\) nominal mesmo com razões de variância de 2:1 a 4:1 (7,9,10).
Razões acima de 9:1 com grupos desbalanceados seriam motivo de maior preocupação.
Os pressupostos estão suficientemente atendidos para validar os resultados da ANOVA mista. A violação da homogeneidade deve ser reportada junto com a justificativa do n balanceado.
16.3.4 Testes post hoc
Efeitos simples de tempo dentro de cada grupo
emm_tempo <- emmeans(modelo_ez2, ~ tempo | grupo)
pairs(emm_tempo, adjust = "bonferroni")grupo = caso:
contrast estimate SE df t.ratio p.value
t0 - t1 -30.2 4.45 80 -6.779 <.0001
t0 - t2 -54.6 5.15 80 -10.601 <.0001
t1 - t2 -24.4 5.28 80 -4.626 <.0001
grupo = controle:
contrast estimate SE df t.ratio p.value
t0 - t1 -7.8 4.45 80 -1.752 0.2508
t0 - t2 -27.8 5.15 80 -5.395 <.0001
t1 - t2 -20.0 5.28 80 -3.785 0.0009
P value adjustment: bonferroni method for 3 tests Efeitos simples de grupo em cada momento
emm_grupo <- emmeans(modelo_ez2, ~ grupo | tempo)
pairs(emm_grupo, adjust = "bonferroni")tempo = t0:
contrast estimate SE df t.ratio p.value
caso - controle -9.51 9.54 80 -0.997 0.3219
tempo = t1:
contrast estimate SE df t.ratio p.value
caso - controle 12.88 10.20 80 1.267 0.2088
tempo = t2:
contrast estimate SE df t.ratio p.value
caso - controle 17.32 10.80 80 1.597 0.1141Interpretação da interação:
Os dois grupos melhoram ao longo do tempo, mas com trajetórias distintas. O grupo caso apresenta melhora significativa em todos os intervalos — inclusive de t0 para t1 (p < 0,0001). O grupo controle, por sua vez, não apresenta mudança significativa entre t0 e t1 (p = 0,251), com a melhora ocorrendo apenas a partir de t1. Essa diferença na velocidade de mudança inicial é o que sustenta a interação significativa.
Em nenhum momento isolado os grupos diferem significativamente entre si — o que é consistente com o efeito principal de grupo não significativo.
A Figura 16.6 confirma visualmente o padrão encontrado no post hoc. Algumas observações:
Em t0, o grupo caso parte de uma média ligeiramente inferior ao controle (~175 vs ~184).
Entre t0 e t1, o grupo caso apresenta um salto expressivo (+30 pontos), enquanto o controle praticamente não muda (+8 pontos, n.s.) — essa é a origem da interação.
Entre t1 e t2, as duas linhas sobem com inclinações similares, convergindo para médias próximas em t2.
As barras de erro (IC 95%) das médias marginais estimadas se sobrepõem em todos os momentos, consistente com o efeito principal de
gruponão significativo.
16.3.5 Tamanho do Efeito Padronizado
O TEP extraído será o eta quadrado generalizado (GES) que é o mais recomendado para a ANOVA Mista. Para executar essa ação, será utilizada a função eta_squared() do pacote effectsize (11). Essa função pode retornar o \(eta^{2}\) , \(eta^{2}\) parcial e o \(eta^{2}\) generalizado. O padrão é o \(eta^{2}\) parcial , portanto deve-se especificar com o argumento o tipo de \(eta^{2}\) desejado.
Eta quadrado generalizado dos efeitos principais e da interação
eta_g <- effectsize::eta_squared(modelo_ez2, generalized = TRUE)
effectsize::interpret_eta_squared(eta_g)# Effect Size for ANOVA (Type III)
Parameter | Eta2 (generalized) | 95% CI | Interpretation
----------------------------------------------------------------
grupo | 5.68e-03 | [0.00, 1.00] | very small
tempo | 0.12 | [0.05, 1.00] | medium
grupo:tempo | 0.02 | [0.00, 1.00] | small
- Observed variables: All
- One-sided CIs: upper bound fixed at [1.00].
- Interpretation rule: field2013Efeito | η²g | IC 95% inf. | IC 95% sup. |
|---|---|---|---|
Grupo (entre-sujeitos) | 0.005682353 | 0.000 | — |
Tempo (intra-sujeitos) | 0.120077765 | 0.048 | — |
Grupo × Tempo (interação) | 0.016306245 | 0.000 | — |
A saída do código do effectsize , usada para criar a Tabela 16.6, mostra que o efeito do tempo tem magnitude grande (η²g = 0,12), o que indica que aproximadamente 12% da variância dos escores (excluindo a variância do erro entre-sujeitos) é explicada pela mudança ao longo dos momentos. A interação grupo × tempo tem magnitude moderada (η²g = 0,02), e o efeito principal de grupo é negligenciável (η²g < 0,0057).
16.3.6 Conclusão
A análise da ANOVA mista revelou que o fator tempo exerceu um efeito significativo sobre os valores de Peak Flow (F(2,160) = 68.725, p < 0.001, ges = 0.120), indicando uma evolução consistente da função pulmonar ao longo das avaliações. Além disso, observou‑se uma interação significativa entre grupo × tempo (F(2,160) = 8.348, p < 0.001, ges = 0.016), demonstrando que a trajetória de melhora diferiu entre os grupos. O efeito principal de grupo, entretanto, não foi significativo (F(1,80) = 0.544, p = 0.463, ges = 0.006), sugerindo que as diferenças globais entre os grupos não são suficientemente robustas quando se considera a variabilidade total.
As análises post hoc com correção de Bonferroni mostraram que, embora o grupo caso tenha apresentado médias superiores em t1 e t2, as comparações diretas entre grupos em cada tempo não atingiram significância estatística (t0: p = 0.305; t1: p = 0.212; t2: p = 0.101). Esses resultados indicam que, apesar da tendência favorável ao novo corticoide, as diferenças pontuais entre grupos não são estatisticamente confirmadas após ajuste conservador.
Por outro lado, a análise dentro dos grupos mostrou um padrão claro: o novo corticoide promoveu uma melhora acentuada e progressiva, com diferenças significativas entre todos os momentos avaliados, enquanto o corticoide padrão apresentou melhora mais lenta, sem alteração significativa entre t0 e t1. O tamanho do efeito generalizado (GES) reforça essa interpretação: o efeito do tempo foi moderado a forte (ges = 0.120), enquanto a interação grupo × tempo apresentou efeito pequeno, porém significativo (ges = 0.016), compatível com diferenças na trajetória de evolução, mas não necessariamente nas comparações pontuais.
Em síntese, os resultados indicam que o novo corticoide proporciona melhora clínica mais rápida e mais pronunciada na função pulmonar, ainda que as diferenças entre grupos em cada tempo isolado não tenham alcançado significância estatística (Figura 16.8). A combinação dos achados — significância da interação, padrão dos post hocs e magnitude dos tamanhos de efeito — sugere que o novo tratamento apresenta vantagem terapêutica relevante, especialmente no ritmo e intensidade da recuperação do Peak Flow.
modelo <- dadosL_mista |>
rstatix::anova_test(dv = escores,
wid = id,
within = tempo,
between = grupo,
type = 3)
pwc <- dadosL_mista |>
dplyr::group_by(tempo) |>
pairwise_t_test(escores ~ grupo,
paired = TRUE,
p.adjust.method = "bonferroni")
pvalores <- dadosL_mista |>
group_by(tempo) |>
pairwise_t_test(escores ~ grupo,
paired = TRUE,
p.adjust.method = "bonferroni") |>
mutate(y.position = 250)
ggpubr::ggline(dadosL_mista,
x = "tempo",
y = "escores",
color = "grupo",
palette = "d3",
linewidth = 0.7,
linetype = "dashed",
add = "mean_ci",
error.plot = "errorbar",
position = position_dodge(width = 0.3),
point.size = 1.5,
ylab = "Pico de Fluxo Expiratório (l/min)",
xlab = "Momento",
legend = "top",
ggtheme = theme_classic()) +
theme(legend.position = "top")+
geom_text(data = pvalores,
aes(x = tempo,
y = y.position,
label = paste0("p = ", signif(p, 3))),
inherit.aes = FALSE, size = 4) +
scale_x_discrete(limits = c("t0", "t1", "t2"),
labels = c("Basal", "45 dias", "90 dias")) +
labs(subtitle = get_test_label(modelo, detailed = TRUE),
caption = get_pwc_label(pwc),
color = NULL)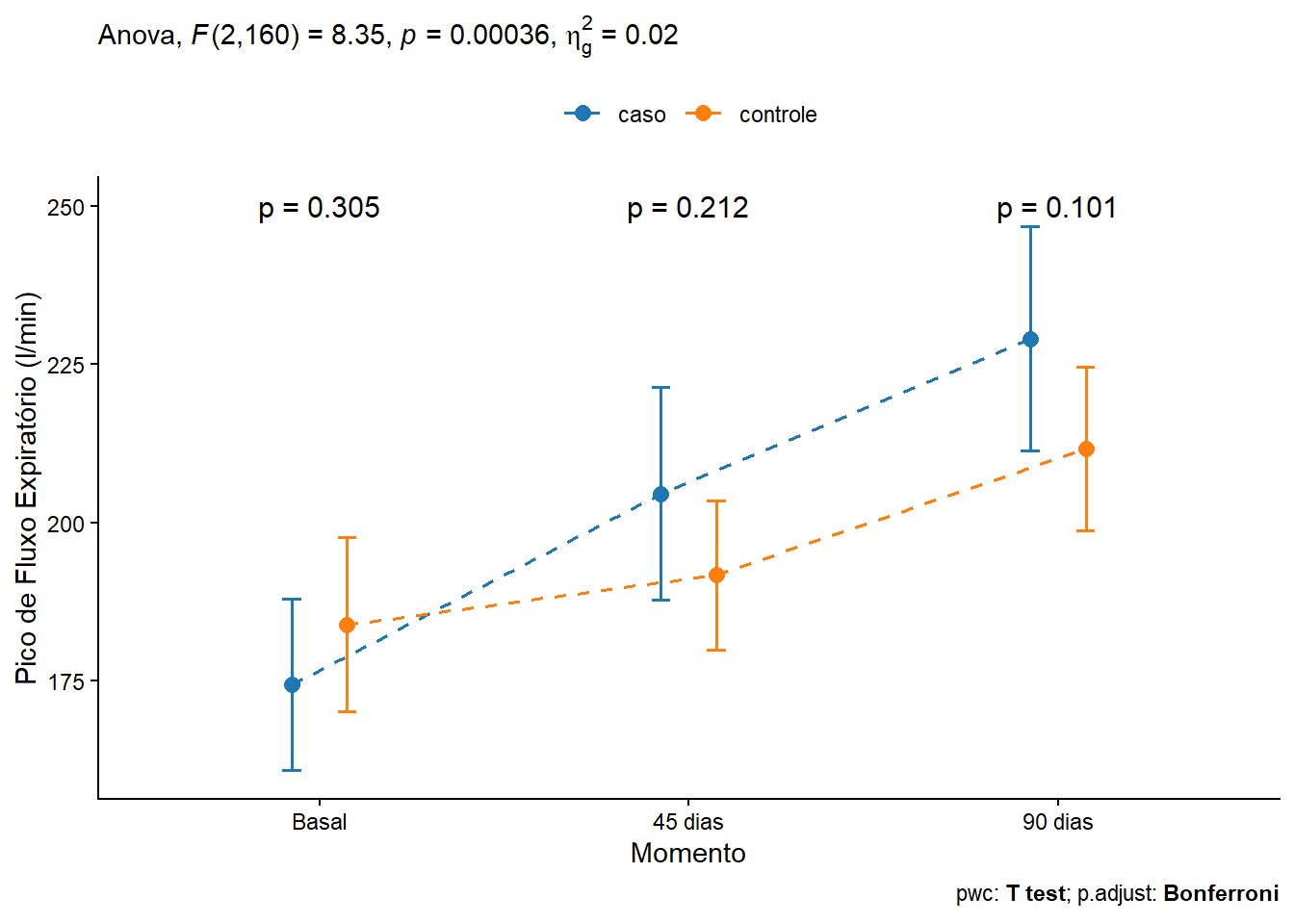
Referências
1.
Anunciação L. Conceitos e análises estatisticas com R e jasp [Internet]. ANOVA de medidas repetidas. 2021. Disponível em: https://bookdown.org/luisfca/docs/anova-de-medidas-repetidas.html
2.
Wickham H, Girlich M. tidyr: Tidy Messy Data [Internet]. 2022. Disponível em: https://CRAN.R-project.org/package=tidyr
3.
Singmann H, Bolker B, Westfall J, Aust F, Ben-Shachar MS. afex: Analysis of Factorial Experiments [Internet]. 2025. Disponível em: https://CRAN.R-project.org/package=afex
4.
Huynh H, Feldt LS. Estimation of the Box correction for degrees of freedom from sample data in randomized block and split-plot designs. Journal of Educational Statistics. 1976;1(1):69–82.
5.
Girden ER. Two-Factor Studies with Repeated Measures on Both Factors. Em: ANOVA: repeated measures. Sage; 1992. p. 31–40. (QASS Series; vol. 84).
6.
Muller KE, Barton CN. Approximate power for repeated-measures ANOVA lacking sphericity. Journal of the American Statistical Association. 1989;84(406):549–55.
7.
Field A, Miles J, Field Z. Discovering Statistics Using R. London: SAGE Publications; 2012.
8.
Tabachnick BG, Fidell LS. Using Multivariate Statistics. 6.ª ed. Boston: Pearson; 2013.
9.
Howell DC. Statistical Methods for Psychology. 8.ª ed. Belmont, CA: Cengage Learning; 2013.
10.
Maxwell SE, Delaney HD. Designing Experiments and Analyzing Data: A Model Comparison Perspective. 2.ª ed. Mahwah, NJ: Lawrence Erlbaum Associates; 2004.
11.
Ben-Shachar MS, Lüdecke D, Makowski D. effectsize: Estimation of effect size indices and standardized parameters. Journal of Open Source Software. 2020;5(56):2815.